Corentin Mercier’s talk on how to reduce the carbon footprint of the cluster covers the following topics > The energy consumption of the cluster > Solutions to reduce it > The new system to shut down idle nodes and its user manual > Estimations of the energy saved thanks to the new system > What users can do to help
In order to proceed with the annual total electric shutdown of the building scheduled on June 11th, we have to shut down the PlaFRIM infrastructure from June 10th during the afternoon. The restart is scheduled on Monday June 13th during the day. We will take advantage of this stop to update SLURM to the latest available stable version. Thank you for your understanding.
Positionnement de Plafrim: machine expérimentale, avec une diversité de types de machines disponibles. Le passage à l’échelle des programmes doit être fait sur d’autres clusters (mésocentre, GENCI, …)
Changement dans Slurm: sans aucune contrainte sur le job, Slurm va attribuer des machines suivant cette liste de priorités: d’abord les zondas (pas de réseau rapide, ni GPUs, …), puis miriel (vieux), puis bora, puis les autres types de machines plus spécifiques (GPU, ARM, mémoire, …). Ce changement devrait être communiqué et documenté rapidement. Pour demander un type de machine particulier, il faut utiliser l’option -C des commandes Slurm (voir https://www.plafrim.fr/hardware-documentation/). On évite ainsi des donner des machines aux caractéristiques particulières à des jobs qui n’utilisent pas ces caractéristiques.
Il y a maintenant une queue preempt dans laquelle les jobs sont exécutés quand la machine n’est pas utilisée, mais ils peuvent être préemptés si d’autres jobs arrivent. Il faut avoir un système de checkpointing pour bien en profiter.
Besoins matériels rapportés:
GPUs récents
Quelques nœuds avec GPUs et beaucoup de mémoire comme sirocco21
Des nœuds avec réseau rapide et beaucoup de RAM pour les gros problèmes de simulation 3D, mais PlaFRIM ne pourra pas en avoir beaucoup, il faut rapidement passer au MCIA
Pas besoin de gros nœud pour remplacer souris/brise, diablo05 suffit la plupart du temps
Noeuds ARM avec GPU et réseau rapide, voire RISC-V, si possible proche de ce qui risque d’arriver dans le projet Exascale France et/ou EPI.
Encore trop tôt pour les FPGA mais continuer à surveiller (comme toujours, essayer d’avoir les machines qui seront demain dans les grands centres de calculs)
Un dataverse pour stocker des données, y compris pour la reproductibilité (voir avec JM Frigerio de l’INRAE)
Besoins logiciels rapportés:
Pouvoir utiliser des nœuds Plafrim comme runner GitLab ou slave Jenkins (les vieilles machines mistral avec des GPU pourraient être utilisées pour ça)
Une interface REST pour soumettre sans passer par la ligne de commande
Avoir une contrainte comme ‘mpi’ pour signaler les nœuds qui ont un réseau rapide (mais il faudrait que slurm prenne des nœuds dans la même partition pour que mpi marche)
Beaucoup de points peuvent être améliorés dans la documentation (sur plafrim.fr):
Expliquer les warnings souvent rencontrés avec MPI et les réseaux rapides
Comment migrer vers un cluster plus important ? (quels clusters sont disponibles, comment migrer son application et ses données)
Documenter la politique d’utilisation, que faire quand on constate un abus
Documenter la version de SLURM installée pour les fonctionnalités avancées comme les jobs héterogènes
Besoin d’éducation par rapport à la politique d’utilisation de Plafrim:
Pas de quota ni de créneaux horaires différenciés pour simplifier les règles d’utilisation et la configuration de Slurm
En échange: utilisation “raisonnée” de la plateforme, ne pas monopoliser tous les nœuds d’un certain type pendant trop longtemps (voir Good usage rules de https://www.plafrim.fr/wp-content/uploads/2015/09/2015_09_charte_plafrim_en.pdf). Si on souhaite utiliser beaucoup de nœuds pendant beaucoup de temps, c’est sans doute signe qu’il faut plutôt utiliser un autre cluster plus grand.
En cas de besoin exceptionnel (publication, …) qui nécessite de monopoliser des nœuds de calcul sur un temps déterminé, une demande pourrait être adressée au Comité Utilisateurs qui donnera son avis et son accord. Ce type de demande est déjà mis en pratique au MCIA.
Si un abus est constaté, ne pas hésiter à contacter le comité technique ou utilisateur.
Nécessité de mieux expliquer cette politique d’utilisation, peut-être dans le mail de confirmation de création du compte
Ne pas hésiter à contacter le comité utilisateur ou technique pour un usage qui sortirait des Good usage rules
Rajouter des informations dans le mail envoyé quand un compte PlaFRIM est créé.
Users are now allowed to use the squeue command on the devel nodes through sudo, to display information about all jobs.
sudo squeue
squeue is the only command for which information about all users will be made available to all, as its information are not a breach to the GPDR related constraints.
Standard nodes miriel[001-088] and K40M nodes sirocco[01-05] are in best effort and without support, and will be removed from the platform when failing to start.
Dear all,
A PlaFRIM discussion team is now available on the Inria mattermost
server. PlaFRIM users got an an email with the link to join.
This team is intended for discussions on any subject related to the use
of the platform. Channels can be created for some specific needs. In any
cases, here some rules to follow
- DO NOT USE any channel to report tickets, sending an email to the
technical team plafrim-support AT inria.fr is the only way to submit tickets.
- Refrain from having NON-SERIOUS conversations or trolls.
For those not having Inria email addresses, an external account must be
created for you to access the mattermost server. Please send an email
back to nathalie.furmento AT labri.fr if you need such an account.
Cheers,
The PlaFRIM technical team
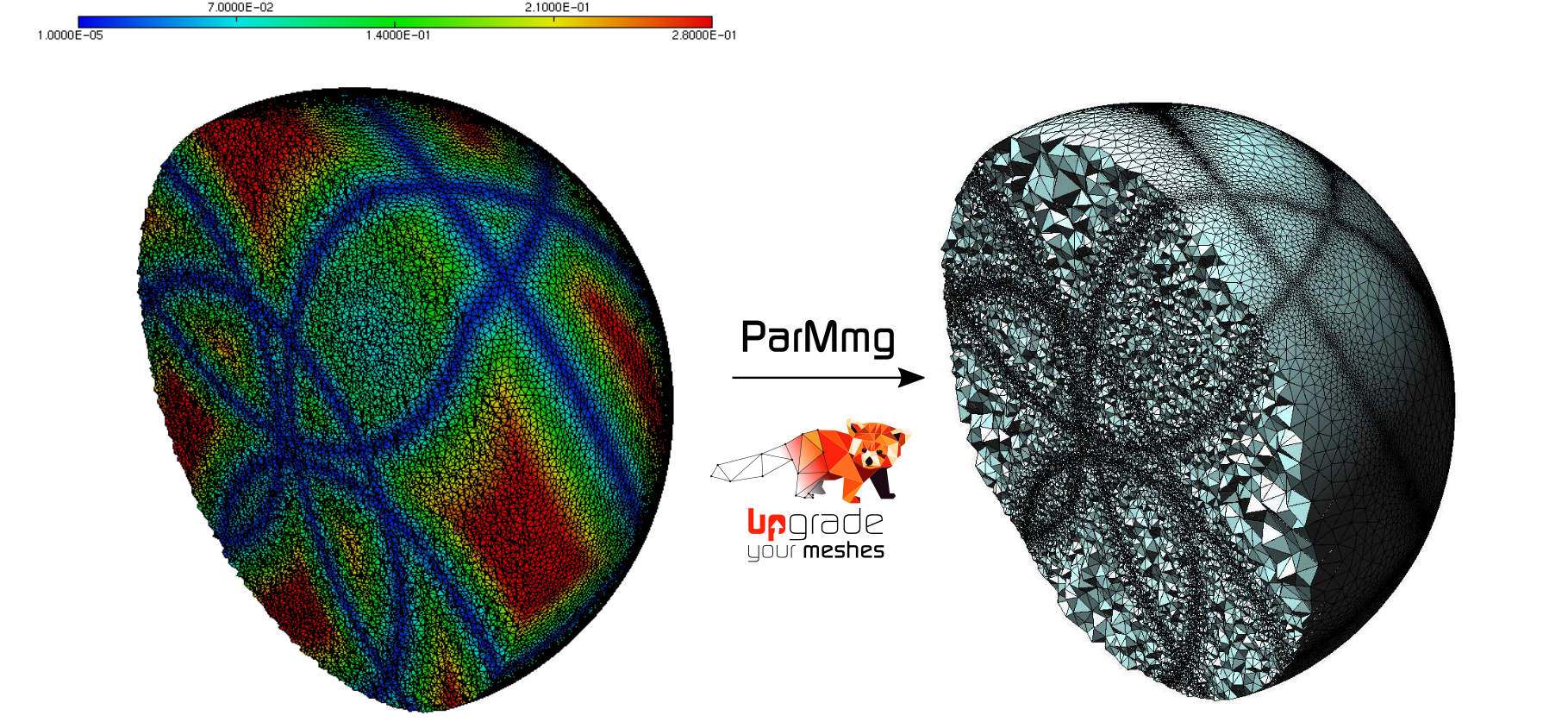
ParMmg is an open source software (L-GPL) that performs 3D parallel mesh adaptation using MPI parallelization.
Mesh adaptation is an iterative process that allows to optimize the density and orientation of the elements of a computational mesh with repect to user needs (maximal admissible error over numerical solutions, boundaries representation, etc…). ParMmg is built on top of the Mmg software and aims at having the same capabilities, both in term of options than in term of usability:
– mesh quality improvement;
– isotropic and anisotropic mesh adaptation with respect to a user size-map;
– isosurface discretization;
– user friendly API.
The ParMmg developement is currently founded by the ExaQUte european project in which ParMmg will provide parallel mesh adaptation for the massively parallel simulations of the partners (few thousands of cores).
You can already use, download and try ParMmg, either as a standalone application, either through other software that interface us:
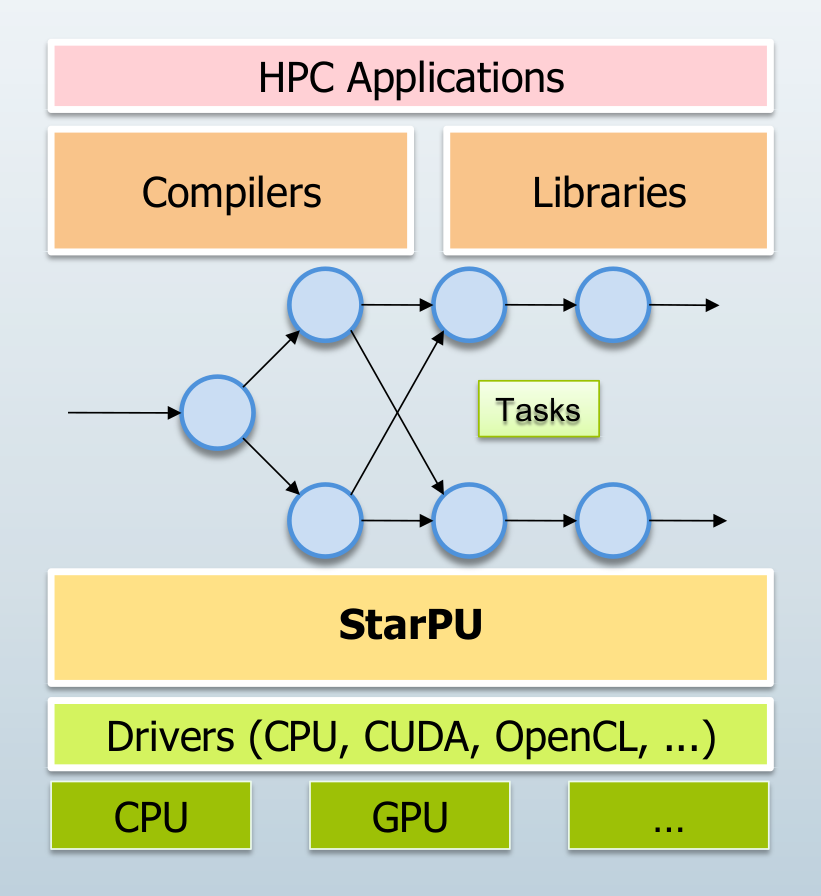
The teams HiePACS, Storm and Tadaam have been cooperating for more than a decade now, on developing the idea of building numerical solvers on top of parallel runtime systems.
From the precursory static/dynamic scheduling experiments explored in the PhD of Mathieu Faverge defended in 2009 to the full-featured SolverStack suite of numerical solvers running on modern, task-based runtime systems such as StarPU and PaRSEC, this idea of delegating part of the optimization process from solvers to external system as been successful. The communication library NewMadeleine is also part of this HPC software stack.
PlaFRIM has always been a key enabling component of these collaborations. Thanks to its heterogeneous computing units (standard nodes, GPU, Intel KNL, Numa nodes, …), the development and validation of our software stack have been made easier. Multiple collaborations with national and international universities and industrials have also been made thanks to our use of the platform.
Contact : Olivier Aumage oliver.aumage AT inria.fr
To generate photo-realistic images, one needs to simulate the light transport inside a chosen virtual scene observed from a virtual viewpoint (i.e., a virtual camera). A virtual scene is obtained by modelling (or measuring from the real-world) the:
– shapes of the objects and the light sources,
– the materials reflectance and transmittance
– the spectral emittance of the light sources.
Simulating the light transport is done by solving the recursive Rendering Equation. This equation states that the equilibrium radiance (in Wm-2sr-1 per wavelength) leaving a point is the sum of emitted and reflected radiance under a geometric optics approximation.
The Rendering Equation is therefore directly related to the law of conservation of energy.The rendering equation is solved with Monte-Carlo computations In the context of Computer Graphics, a Monte-Carlo sample is a geometric ray carrying radiance along its path, which is stochastically (e.g., using Russian roulette) constructed.
PlaFRIM permits researchers in Computer Graphics to simulate billion of light paths/rays to generate reference images for a given virtual scene.
These data can be used to validate:
– new models that predicts how light is scattered by a material
– new rendering algorithm that are more efficient in terms of variance but also in terms of parallelism.
Indeed, PlaFRIM offers a large palette of computing nodes (CPU, bi-GPU) that permit us to develop, test and validate the whole rendering pipeline.
Contact: Romain Pacanowski romain.pacanowski AT inria.fr
Following the policy update of the partition usage, defq is no longer
available. You need to use the parameter -p of srun & co to specify a
partition. Calling sinfo will show you all the available partitions.
This solution is temporary until Nov, 12th, when the new platform will
be available.