A KNL based cluster (Knights Landing (KNL) ) has been installed in February 2017.
The cluster consists of 4 KNL interconnected by OmniPath.
Knights Landing (7230) is a highly configurable architecture. Memory bandwidth is one of the common bottlenecks for performance in computational applications. KNL offers a solution to this problem.
To do so, the 2nd generation of Intel Xeon Phi (KNL) has on-package high-bandwidth memory (HBM) based on the multi-channel dynamic random access memory (MCDRAM). This memory is capable of delivering up to 5x performance (≥400 GB/s) compared to DDR4 memory on the same platform (≥90 GB/s).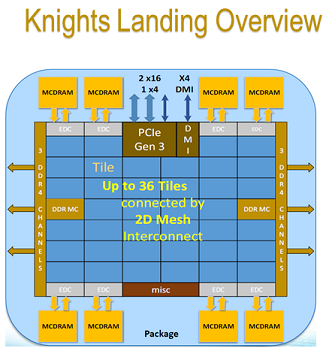
The on-package HBM (labeled “MCDRAM” in the figure) resides on the CPU chip, next to the processing cores. KNL may have up to 16 GB of HBM. It’s hyghly configurable. The modes (which can only be modified through the BIOS) are the following:
More information is available in this Intel tutorial.
KNL have 64 cores (7230 version) and are organized on a grid as follows: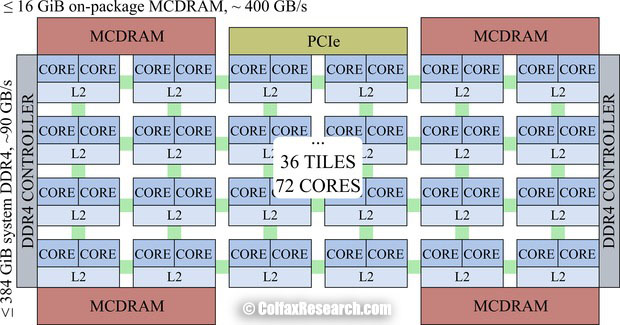
- 32 tiles of 2 cores each with a L1 cache, and 1 shared L2 cache.
- all shared L2 cache are interconnected by the grid. MESIF protocol is in charge to keep all the caches coherent
- all links are bidirectionnal
- KNL has a distributed tag directory (DTD), organized as a set of per-tile TD (tag directories), which identify the state and the location on the chip of any cache line. It is in the developer’s interests to maintain locality of these messages to achieve the lowest latency and greatest bandwidth of communication with caches. KNL supports the following cache clustering modes:
- all-to-all
- quadrant / hemisphere
- SNC-4 / SNC-2
More information is available in the colfax documentation.
To allow users to test the different configurations, the 4 nodes of the cluster have all been configured with different parameters. Information on the different configurations is available in the PlaFRIM hardware page.